1. Considerazioni generali
Nei capitoli successivi vengono presentati i risultati di un ampio questionario somministrato a più di 600 frequentatori di centri sociali romani. Tali risultati vengono presentati sotto forma di tabelle, poco meno di un centinaio (sono tante, ce ne rendiamo perfettamente conto, e con tutta probabilità ciò costituirà un appesantimento per il lettore). Il nostro obiettivo è stato tuttavia quello di presentare i risultati delle interviste nel modo più pulito e trasparente possibile (anche se rimaniamo ben consapevoli del fatto che pulizia e trasparenza nella presentazione dei dati e nel loro collegamento con la realtà sono pure e semplici utopie).
Il questionario, qualsiasi questionario, è di per sé una violenza perpetrata ai danni dell’intervistato, specialmente se costui si trova a dover scegliere fra risposte “chiuse” e preconfezionate: è una violenza alla ricchezza e alla articolazione dei contenuti che egli vorrebbe esprimere. D’altra parte, l’elaborazione statistica complessa dei dati che emergono dai questionari costituisce una ulteriore violenza, proprio perché significa prendere per buoni, autentici e non ambigui i dati di partenza su cui si basa. Non è questa la sede per impostare un discorso critico in merito all’uso ideologico e distorto che viene fatto dei dati e della loro manipolazione statistica. Sappiamo che il pil non misura la ricchezza né tanto meno la felicità o il benessere di una collettività, che il tasso di inflazione è un dato manipolato e finto, che nessuno è in grado di dire (o vuole dire) -nonostante tutto- a quanto ammonta l’evasione fiscale o chi sono i veri grandi possessori di bot.
La nostra scelta è stata quella di adottare un’ottica di documentazione, orientata al rendere il più semplice possibile la lettura dei dati originari. Le tabelle che presentiamo descrivono, per ogni domanda contenuta nel questionario, le frequenze delle varie risposte fornite dagli intervistati. In particolare, abbiamo scelto di riportare sempre le frequenze assolute, e cioè il numero esatto degli intervistati che hanno scelto ciascuna risposta.
Questo per facilitare e rendere possibile una valutazione da parte del lettore circa l’esito di ciascuna domanda. Le percentuali sono state utilizzate esclusivamente affiancandole alle frequenze assolute da cui sono state derivate. Accanto alle tabelle semplici, abbiamo fatto un largo uso delle tabelle incrociate, dove vengono confrontate le risposte date dagli intervistati a coppie di domande: in queste tabelle, in sostanza viene visualizzato come hanno risposto alla domanda X tutti gli intervistati che hanno risposto in un determinato modo alla domanda Y: della lettura e del significato di queste tabelle se ne parlerà fra breve.
Solitamente l’accostamento delle risposte a due diverse domande è il primo passo che in sede di elaborazione statistica viene compiuto per provare a determinare delle relazioni causali e per semplificare dei fenomeni complessi. Per quanto ci riguarda, abbiamo scelto di operare tale accostamento più che altro per completezza di informazione. Non siamo interessati infatti a fornire letture “sociologiche” sintetiche e ad accodarci in questo a quanti l’hanno già fatto, senza confrontarsi in modo diretto e esplicito con le realtà dei centri sociali. Come si potrà notare, non è rintracciabile nel lavoro nessun riferimento esplicito e sistematico a giudizi di valore o causali che coinvolgano concetti generali quali “i frequentatori dei centri sociali”, “i giovani”, “i centri sociali”, ecc. ecc..
I dati che presentiamo vengono descritti e utilizzati per quello che sono, ossia il risultato di 628 interviste effettuate in 16 centri sociali di Roma nella primavera del 1994. Niente di più e niente di meno. In sostanza, non si tratta di un sondaggio né tanto meno di una indagine di mercato, ma di una pura e semplice descrizione di una collettività di intervistati. Non ha senso, perché per noi non ha senso, parlare di una indagine campionaria o di rappresentatività del campione di intervistati. Ovviamente, se si prendono come parametro le cosiddette indagini campionarie normalmente spacciate sui quotidiani o dai centri di ricerca sociale che vanno per la maggiore, il presente lavoro avrebbe una piena legittimità a essere considerato una indagine campionaria.
Ma, lo ripetiamo, non è questo il nostro interesse. Siamo piuttosto convinti del fatto che le evidenze che riportiamo possano costituire un utile strumento di dibattito, di confronto, di critica e di conoscenza per i compagni che frequentano o operano nei centri, per i compagni che nei centri sociali non ci hanno mai messo piede, e anche per chi compagno non è affatto. I dati contenuti in questo lavoro descrivono una realtà decisamente complessa, che ben difficilmente può essere sintetizzata con indicatori statistici complessi, se non al costo di perdere di vista quanto si sta descrivendo. E’ anche per questo che l’unica maniera praticabile per descrivere questa realtà ci è sembrata quella di descriverla mantenendo il più possibile intatta la complessità e la straordinaria varietà che emerge dalle risposte date ai questionari.
In quanto segue, riportiamo una breve guida al significato del campionamento e dell’indagine campionaria e alla lettura delle tabelle, a beneficio di coloro i quali hanno meno dimestichezza con le statistiche.
2. Brevi annotazioni sulle indagini campionarie
Solitamente, nei manuali di statistica il capitolo sul campionamento viene introdotto facendo riferimento al comportamento usuale dell’essere umano. Il sapere, le conoscenze, la propria posizione, vengono tutti acquisiti, nella sostanza, attraverso processi induttivi che, da un insieme limitato di esperienze, consentono di passare a una rappresentazione del tutto (che ovviamente non coincide con il concetto di conoscenza “assoluta” del tutto). Nella statistica il processo induttivo raggiunge una formulazione tecnica (o meglio sarebbe dire “più formulazioni tecniche”) proprio nel capitolo del campionamento, che affronta il tema della rappresentatività di un particolare collettivo (campione) rispetto a un collettivo più vasto dal quale è stato tratto. E’ evidente che la conoscenza del tutto attraverso una sua parte non è altro che una presunzione, sicuramente comprensibile ma molto spesso non giustificabile. Al di là di casi particolari, che sicuramente non fanno parte del campo dell’indagine sociale, non vi è alcun metodo razionale per farci arrivare alla conoscenza esatta del tutto. La fiducia che talvolta si pone nelle potenzialità delle indagini campionarie è frutto soprattutto di una illusione, frutto a sua volta dell’uso massiccio dell’apparato matematico-formale che nasconde le insufficienze logiche che sono alla base del problema dell’induzione. E’ per questo insieme di motivi che, pur essendo quella che qui presentiamo una indagine campionaria a tutti gli effetti, ci si è ben guardati dal trarne conseguenze per il tutto (“i frequentatori dei centri sociali romani”). Occorre tuttavia tenere presente che la dicotomia che viene fatta fra indagini censuarie (effettuate, come nel caso dei censimenti, registrando i dati di tutti gli individui della popolazione) e indagini campionarie è spesso ingannevole: alle prime viene attribuito un presupposto di completezza che invece sovente non hanno, per problemi e difficoltà di vario genere a cui vanno incontro, non ultimo a causa della gran mole di dati e di informazioni che spesso è necessario raccogliere nei censimenti. L’attività di campionamento è dunque una prassi sicuramente molto diffusa e molto necessaria. E’ senz’altro una tecnica (un insieme di tecniche) che però non avrebbe alcun significato, specialmente nel campo delle indagini sociali, se non fosse continuamente accompagnata da una adeguata attenzione critica. E questo è quanto, pur con limitati mezzi e strumenti, abbiamo cercato di fare.
La scelta del campione è nei fatti la fase più delicata. Il modo più semplice per immaginarlo è quello di scegliere in maniera casuale le unità che fanno parte del campione. Più sovente questa casualità viene in qualche modo limitata. Nel nostro caso, ad esempio, abbiamo scelto di effettuare le interviste nelle ore serali, abbiamo scelto per lo più iniziative musicali e abbiamo scelto di fare interviste in 16 centri sociali: sono scelte consapevoli che senza dubbio qualificano il tipo di rappresentatività cui il nostro campione si approssima. Eravamo infatti interessati a cogliere le modalità di fruizione di frequentatori che non fossero solo quelli abituali: se questa fosse stata la nostra intenzione avremmo scelto di fare le interviste nel pomeriggio, in serate infrasettimanali prive di iniziative, nel corso di iniziative di tipo organizzativo interno, probabilmente estendendo l’indagine a tutti i centri sociali romani.
Altra fase delicata, per una indagine come quella qui presentata, è quella relativa alla elaborazione del questionario, che deve essere comprensibile per l’intervistato, deve prestarsi alla codifica statistica, e deve permettere il controllo incrociato fra le domande. Un compito questo che, nonostante le molte ore spese collettivamente nella costruzione del questionario, non ci è riuscito del tutto, tanto è vero che più di una domanda è risultata inutilizzabile. Prima di avviare la rilevazione e le interviste è tuttavia consigliabile effettuare una “indagine-pilota”, ossia un vero e proprio esperimento attraverso il quale testare gli eventuali inconvenienti presenti nel questionario e apportare per tempo le opportune correzioni. Gli inconvenienti più abituali sono numerosi: le formulazioni generiche, la ricerca di opinioni su alternative mal specificate, la mancata rispondenza fra il tipo di domanda e la cultura (in senso lato) dell’intervistato, la non univocità del significato della domanda, l’eccessivo sforzo di memoria che può richiedere una domanda, l’eventualità che una domanda sia formulata in modo da condizionare la risposta, la possibilità che la domanda coinvolga l’autovalutazione dell’intervistato, e via dicendo.
3. La lettura delle tabelle semplici
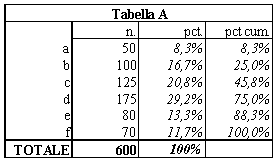
Quella che segue è una tabella fittizia che rappresenta la distribuzione delle risposte fornite a una qualsiasi singola domanda del questionario. La prima colonna a sinistra rappresenta il complesso delle risposte possibili -le modalità (a,b,...,f): l’ultima riga è quella dei totali. La seconda colonna è quella delle frequenze assolute, riportate sotto la dicitura “n.”, e riporta il numero di intervistati che hanno scelto ciascuna modalità. Nell’esempio, 50 intervistati hanno scelto la risposta “a”, 100 la risposta “b”, 125 la “c”, ecc.. Il totale degli intervistati è 600.
La terza colonna riporta le percentuali semplici (o frequenze relative) sotto la dicitura “pct.”. L’8,3% degli intervistati (ossia poco più di 8 intervistati ogni 100) ha scelto la risposta “a” . Sulla riga del totale, in corrispondenza della colonna “pct.” appare il numero 100%. La distribuzione percentuale riproduce quella delle frequenze assolute nel caso in cui il totale degli intervistati fosse esattamente pari a 100. L’utilizzo delle percentuali serve per rendere più agevole la lettura della tabella e il confronto fra le singole risposte, e anche per confrontare fra loro - quando ciò ha un qualche senso - tabelle diverse.
La quarta colonna riporta le percentuali (o frequenze) cumulate (“pct.cum.”). Queste possono essere utilizzate solo nel caso in cui le modalità (a,..,f) siano ordinabili. Un caso di questo genere si presenta quando tali modalità siano, ad esempio, classi di età, dove “a” è la classe di età più giovane, “b” quella appena superiore, e così via fino a “f”, la classe di età più elevata. Il 45,8% che appare in corrispondenza della modalità “c” sta dunque ad indicare che 45,8 intervistati su 100 ha un’età uguale o inferiore a quella della classe “c”. Ovviamente in corrispondenza dell’ultima classe di età (“f”) la percentuale cumulata è pari al 100%, perché tutti gli intervistati hanno un’età inferiore o al più uguale a quella della classe “f”. Le percentuali cumulate servono per visualizzare e quantificare il grado di concentrazione di una distribuzione. Se infatti la gran parte degli intervistati appartiene alle classi di età più giovani, le percentuali cumulate risulteranno molto elevate fin dalle prime classi di età. Viceversa nel caso opposto.
4. La lettura delle tabelle incrociate
Quella che segue è una tipica tabella incrociata. Vengono messe insieme le risposte alla domanda X e alla domanda Y. La domanda X è esattamente quella adottata nell’esempio precedente. Le sue modalità (a,...,f) sono riportate nelle righe. La domanda Y ha modalità (r,s,t,u,v), poste nelle colonne. La tabella è divisa in due parti: quella dove sono riportate le frequenze assolute e quella dove sono riportate le percentuali colonna. Cominciamo dalle frequenze assolute.
Nell’ultima colonna a destra sono riportati i totali della domanda X, che poi sono gli stessi di quelli riportati nella tabella semplice precedente. Solo che adesso abbiamo una ulteriore informazione. Infatti risulta che dei 50 che hanno risposto “a” alla domanda X in 10 hanno risposto “r” alla domanda Y, in 5 hanno risposto “s”, in 20 hanno risposto “t”, e così via. Lo stesso vale per le altre modalità della domanda X. Ovviamente la tabella può essere letta al contrario. La riga del totale porta i totali delle risposte alla domanda Y. Dei 129 intervistati che a tale domanda hanno risposto “r”, 10 hanno risposto “a” alla domanda X, 20 hanno risposto “b”, 22 hanno risposto “c” e così via. Lo stesso si applica alle altre modalità della domanda Y.
L’uso delle tabelle incrociate è particolarmente interessante se ci si pone la seguente domanda: “Il modo con cui gli intervistati rispondono alla domanda X ha o no una qualche relazione con il modo con cui hanno risposto alla domanda Y, e viceversa?”. E’ utile a tale proposito prendere in considerazione le percentuali.
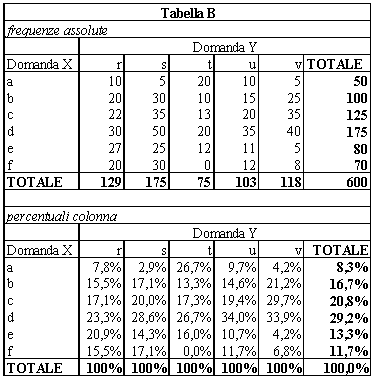
Anche con le percentuali l’esercizio è duplice. Si possono considerare le percentuali riga. In questo caso si ha la descrizione di come si ripartiscono le risposte alla domanda Y dei vari gruppi di intervistati distinti a seconda della risposta che hanno dato alla domanda “a”. Oppure si possono considerare, come nell’esempio, le percentuali colonna. In questo caso la colonna del totale riporta le stesse percentuali semplici della tabella A considerata in precedenza. Queste percentuali possono essere confrontate con quelle che risultano nelle singole colonne corrispondenti alle varie risposte alla domanda Y. Si vede allora che se, nel totale, gli intervistati hanno scelto la risposta “a” nell’8,3% dei casi, considerando i soli intervistati che hanno risposto “r” alla domanda Y tale percentuale scende al 7,8%. Se si considerano gli intervistati che hanno risposto “t” alla domanda Y la stessa percentuale è addirittura del 26,7%. Da una analisi di questo tipo, estesa evidentemente a tutte le modalità della domanda X, possono perciò scaturire stimoli, associazioni e tentativi di spiegazione di quelle differenze. Per esempio: perché è così alta fra gli intervistati che hanno risposto “t” alla domanda Y la percentuale di quelli che hanno risposto “a” alla domanda X rispetto al totale degli intervistati? C’è, o è rintracciabile, una qualche spiegazione? Cosa ci suggerisce questa evidenza? Che relazione c’è con le altre caratteristiche degli intervistati che non sono contenute nelle risposte alle domande X e Y? E così via.
Nel complesso, la presentazione dei dati segue esattamente questa procedura: vengono presentate delle tabelle che, nella maggior parte dei casi pongono e restituiscono quesiti e interrogativi. Nel nostro commento alle tabelle abbiamo cercato di evidenziare tali quesiti, cercando di evitare - se non laddove le risposte apparivano più ovvie e banali - di fornire una nostra lettura univoca e definitiva. Questo soprattutto perché la mole stessa dei dati, nonché il numero stesso degli incroci possibili fra tutte le domande, è del tutto ragguardevole. Basti pensare che con 25 domande esistono 300 incroci possibili, senza contare che possono essere fatti incroci anche con tre domande (qualcuno è stato anche riportato). Il nostro lavoro è sostanzialmente consistito nella scelta (in quanto tale arbitraria) delle tabelle incrociate più interessanti e significative.
5. Alcuni indicatori sintetici
Riportiamo adesso brevemente il significato di alcuni degli indicatori statistici sporadicamente utilizzati per quelle domande in cui le modalità delle risposte erano quantitative (come ad esempio nel caso dell’età).
Iniziamo con la media aritmetica. Facciamo l’esempio dell’età. Si fa la somma delle età dei singoli intervistati e la si divide per il numero degli intervistati. Presi cinque individui, con età di 9, 15, 16, 30 e 30 anni, la somma delle età fa 100, diviso 5 si ottiene 20 anni di età media. Come si può notare l’età media non necessariamente coincide con l’età di un individuo compreso nella popolazione considerata.
Diverso è il caso della mediana. Se si ordinano gli individui secondo l’età, l’età mediana è l’età posseduta dall’individuo che sta esattamente al centro. Nel nostro esempio, l’età mediana è 16 anni. Quando l’età mediana è, come nell’esempio, minore di quella media, ciò sta a significare che sono più frequenti gli individui con una età bassa rispetto a quelli con una età più elevata.
Veniamo infine alla moda. Si tratta dell’età che è maggiormente frequente nella popolazione considerata. Nel nostro esempio l’età modale è 30 anni, perché è posseduta da due individui, mentre le altre età sono posseduta ciascuna da un solo individuo.
Nella nostra analisi abbiamo comunque cercato di usare il meno possibile questi indicatori sintetici, preferendo evidenziare i singoli dati così come emergono dalla rilevazione, senza sintetizzarli ulteriormente. Gli unici indicatori adoperati sono appunto quelli illustrati in precedenza.
 Torna all'inizio della pagina
Torna all'inizio della pagina


Per ogni info, richiesta o commenti
tmcrew@mail.nexus.it
TM Crew c/o Radio Onda Rossa - Via dei Volsci 56, 00185 Roma (Italy)
Tel. + 39 6 491750/4469102 Fax. + 39 6 4463616